Many people across the globe are currently interested in the quality of code and, even more, the quality of results that arise from code. In particular, in the UK, Neil Ferguson’s epidemiological code, that seemed to influence the government’s decision to impose a lockdown, and, on this blog at least, the code that makes up climate models, both GCMs and IAMs. (That’s General Circulation Models and Integrated Assessment Models to their friends.)
This post then is about When Code Goes Wong. Here’s an amusing example.
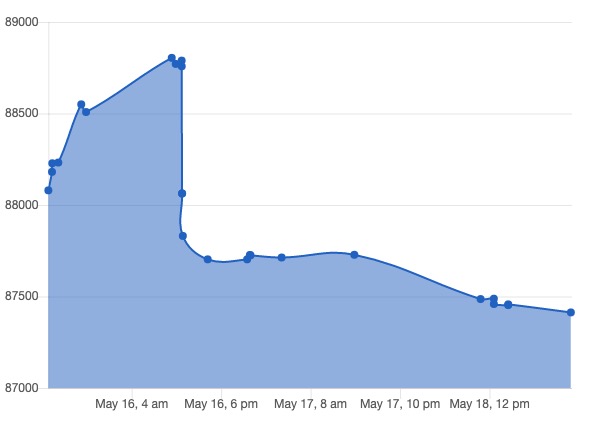
That’s the code size in bytes of a succession of Git commits I made between the 15th and 19th of this month, in doing some ‘real work’ unrelated to Covid-19 or climate. It clearly shows the build phase, where the code size increases, followed by the refactoring one, where the opposite tends to occur (but not always). And in my refactoring I made a couple of stupid errors. My Code Went Wong. And that’s the risk that many coders, like Professor Ferguson, are aware of and wish to avoid. And so code bloat and fragility grows, with little or no regard for the principle of DRY (Don’t Repeat Yourself) or the even more fundamental one of removing ‘dead code’ that will never be used.
However, wrong results are not merely the result of refactoring gone wrong. Commenter Jit summarised the wider situation very well, I thought, talking about the Ferguson model, on our earlier open thread:
Re: the code, well this and the model it built was always going to be trash. I said as much on an earlier thread. If you compound enough unknowns with the unpredictability of human behaviour in a model that has to be spatially structured to be worth anything… you inevitably end up with nothing resembling the real world. I begin to doubt models as soon as they rise above one dimension. Even in the exponential phase, simplest case, if dN/dt = rN then you have two fat unknowns to generate a third. Now add spatial structure and modelled behaviour to make r the mean value of every viral population (i.e. infected person) and you would be lucky to get anything resembling a realistic value, let alone a true value. I wonder how many input parameters it takes? Does it consider the time of year, ambient temperature etc?
No doubt if code has been built over years it is going to be unwieldy with bits bolted on here and there and lurkers that no longer get called.
Nevertheless, it says more about those who show cyber deference than the code’s originators.
It was always going to be trash in the hands of HMG because a) the assumptions were wrong (a point underlined later by John Ridgway) and b) too much deference was shown to the apparent answers given. The age-old process we’ve all heard of and made our contributions to, in our turn: Garbage In Garbage Out.
All the same, having unreadable code doesn’t help. This thread is going to be about just such issues and could get quite long. But I interrupt the fascination with an advert. This afternoon at 5pm BST Christopher Essex is talking via Zoom for the GWPF on “Mathematical Models and Their Role in Government Policy“. Professor Essex has deeply influenced me on the subject of GCMs. I’ll be there. And once I’ve taken in what he and the others have to say, I’ll return to this post.
SO, TO BE CONTINUED
(but feel free to comment, as from now. Thank you for your patience.)

This site
statmodeling.stat.columbia.edu
Has posts on Ferguson , hydroxychloroquine etc. Well worth a look. Annan is there defending Ferg. Bob Ward gets quoted.. the data for the Lancet hydro..quine study can’t be released due to confidentiality agreements. Oh dear.
LikeLiked by 2 people
Richard,
In the interests of strict accuracy, what I said was:
“Any or all of the above may have been valid and reasonable assumptions, and any one of them may have been wrong.”
It’s the uncertainty that is the issue and, as JIT pointed out, the alarming rate at which it can compound itself.
LikeLiked by 2 people
> And so code bloat and fragility grows, with little or no regard for the principle of DRY (Don’t Repeat Yourself) or the even more fundamental one of removing ‘dead code’ that will never be used.
Richard
could you walk me through why dead code removal is ‘even more fundamental’ than DRY?
I’m an inveterate code-hoarder myself, and when code doesn’t spark joy anymore I tend to collapse it in my editor or (more clumsily) comment it out. I wish there were a better solution. But intuitively it would seem to be fairly harmless unless you reactivate said code like a virus from the Siberian permafrost without good documentation as to WHY you abandoned its use to begin with. And I’m fairly sure I’ve profitably resurrected whole methods on at least a few occasions. So am I doing it all wrong? Should I be decluttering instead and, if I really really need to see some extinct code, using version control to revisit it?
LikeLiked by 2 people
Actually, it is the “too much deference was shown to the apparent answers given” statement that I’d rather be associated with. My recent spat with Stephen Mosher started when I tried to emphasise an important principle learned in my days as a top secret, top ranking health and safety manager to the Hollywood stars:
Often in safety matters it is not the gap between the required competence and actual competence that matters so much as the gap existing between the actual competence and the perceived competence. Put simply: Overconfidence kills. So the key question is not just how good the model is, but how good did the government presume the model to be.
LikeLiked by 2 people
Re the subject of redundant code in safety critical software:
When I was the senior functional safety assessor working on safety critical software for the Dalai Lama, I learned the importance of having confidence in a safety case. It was common practice to leave redundant code in place, or even leave known bugs uncorrected, if that was what was necessary to state the case with certainty. Correcting bugs can introduce side effects that are not always possible to identify prior to re-commissioning, thereby reducing rather than increasing confidence in the safety case. For that reason, relatively low level software defects would often be left alone rather than disturb the code.
LikeLiked by 2 people
Thanks to all and apologies to John. Perhaps “a point underlined later by John” should simply have been “a point underlined for me later by John” – because I read that comment and thought “They can’t all have been correct!” I also thought “Good on Dr Ferguson for being explicit about the assumptions in that paper.” I’ll definitely come back to that. But thanks for that contribution. I did want to pull out your and Jit’s comments from the more general conversation as part of having another crack at the Covid/Climate code combo. More after Essex and co this evening.
LikeLiked by 2 people
On dead or redundant code, let me think about it. I would say this: any time refactoring is deemed too risky the fragility of the code has won and entropy can only increase. But I’m not saying that’s not a pragmatic way to proceed with legacy code that is still being relied upon. I’ve never worked in safety critical systems. Or epidemiological modelling. Or climate modelling. The list of areas I’ve not worked in is indeed vast.
Brad: I have a wiki I use to snip key code that I use once (say for a key data transition) and then wish to remove from the current code in the Git repository in question. And I have another repo into which I may move stuff for use elsewhere. The key drivers for me are readability and YAGNI – You Ain’t Gonna Need It. Those two are highly symbiotic I find. But coders, as you no doubt know, work very differently in detail. Tell me more about your context if you’d like.
LikeLiked by 1 person
Richard,
“I’ve never worked in safety critical systems.”
That’s no problem. I can put you in touch with a real expert called Stephen Mosher. He has worked to MIL-STD 2167A and he used to sack people like me on a hunch, don’t you know.
Or, alternatively, you could take advice from a guy I once worked with called Professor John McDermid, OBE, MA (Cantab), PhD (Bham), FREng, CEng, CITP, FBCS, FIET, FSaRS, FRAeS, FHEA, MioD. He’s a good guy and he speaks very highly of me. But there I go again with my uncheckable credentialism!
LikeLiked by 3 people
Here’s a real coder talking. One can tell by the systematic way he went about discovering his own stupidity. I’ve been coding for almost 40 years, so why do I still do stupid things? got my attention because it’s 40 years almost to the day since I joined the consultancy arm of Price Waterhouse as a trainee analyst-programmer, my first commercial software job.
Funnily enough, in the codebase graphed in the main post I devised a rather neat solution to the macOS case-insensitive filename problem that was the cause of Dave Sag’s woes down-under. Before it bit me. At least this time.
I’ll include the above quote in the main post in the next 24 hours or so. But I’ll drip feed additions in comments too. The point here is that the detailed job of coding, done right, makes one humble and uninclined to get on one’s high horse about the flaws you see, or just read about, elsewhere. Or at least it should.
LikeLike
Richard,
I was first introduced to the joys of computer programming when I was a first year student at Newcastle University. The computing department was located in an impressively tall building called the Claremont Tower. As I recall, the card reader one used to feed in the program (yes, we are going that far back) was in a basement room three floors below ground level. The terminal at which one ran the program was located about six floors above ground level. Anyway, I had a great deal of difficulty getting my first program to even compile properly. I cracked it eventually, but I think I had lost six pounds before I finally learned how to spell ‘integer’.
LikeLiked by 1 person
Must be a thing here. I was once pretty familiar with MIL-STD 2167A and the later MIL-STD-498 and DO-178. Don’t recall any clauses about firing people on a hunch though 😉
LikeLiked by 2 people
H’mm, I’m not sure I entirely agree with myself anymore. For, even if the code was pristine, I wouldn’t have believed in the output of the model. I don’t have the skills to judge whether the code is pristine – haven’t programmed (as it was naively called by us tyros back when) since Pascal and my benchmark was normally as low as whether it ran or not.
The point I’m groping towards is that the impact of cyber deference (I may be the only person in the world to call it that) means that as a species we give too much weight to the output of our silicon friends, especially when the modelled problem becomes multi-dimensional and maybe fractal or even chaotic.
(Anyone remember “Morgana” in the arcades in the 1970s? You put in a coin, I think pick your star sign, and a taped movie played over an alabaster bust as Morgana foretold your future. I see the complex epidemiological model that predicted ?500,000? deaths as just a new iteration of Morgana.)
LikeLiked by 2 people
You’re right, JIT. Regardless of the state of the code, a model is only as good as the assumptions that go into making it, which is to say a model is only as perfect as our understanding of the thing being modeled. The phrase “garbage in, garbage out” should never be forgotten when dealing with such things.
LikeLiked by 2 people
In the wake of the UCL modelling revelations there has been a great deal of debate regarding the importance of software standards in the writing of academic software. There are many who argue that the quality of the code is a red herring, or as Steven Mosher put it, people are failing to appreciate the difference between verification and validation. The proposition made is that the software can be perfectly valid even though it fails to meet commercial standards. I tried to point out to Steven why he was talking through his anal sphincter but he dismissed me as the sort of quality control underling that he has always found eminently dismissible.
Mmm. I wonder what the British Computer Society has to say about this:
“In a new policy paper, BCS calls for professional software development standards to be adopted for research that has a critical impact on society, like health, criminal justice and climate change. The underlying code should also be made open-source.
The organisation has also argued there is a lack of widely accepted software development standards in scientific research which has resulted in undermining of confidence in computational modelling, including in high-profile models informing Covid-19 policy.”
https://www.digitalhealth.net/2020/05/bcs-scientific-modelling-codes-should-meet-independent-standards/
Is that checkable enough ‘credentialism’ for you Mosher? Should I start the ball rolling by sacking the BCS for you?
LikeLiked by 2 people
Thanks John, Andy, Jit, DaveJR and all. I’m tardy in making any progress with this but tomorrow I will!
LikeLiked by 2 people
The idea that we should even entertain the use of less than transparent, professional fully disclosed and accountable software to inform major policy decisions rates up there with the use of voodoo.
But we are at the beginning of a dark age, not the end. The beginning of a new state religion, not the end.
LikeLiked by 2 people
Hunterson7,
The mistake being made by some is to believe that software quality is the least of our concerns because even software built to the highest of standards can still be used to get the wrong answer. Whilst this may be true, it doesn’t alter the fact that any attempt to validate a system will always be thwarted by poor quality. One needs to be able to trust the software before we can begin evaluating the answers it gives to a real world problem. The chartered institute for IT professionals understands this and, for what it is worth, so do you and I. It’s not good enough to have a sound model, one needs a sound model soundly implemented in a manner that facilitates external scrutiny. As you say, we don’t need voodoo.
LikeLiked by 2 people
For anyone who is interested, I decided to visit a debate over at ATTP on this very subject in order to post an extract from the BCS press release mentioned above. One would have thought such a contribution would be welcomed, since it involves an organisation run by professionals that exists to promote professional standards within the field. I did expect some unwarranted hostility from the usual suspects but nothing quite prepared me for the extraordinary response the BCS statement received. I tried to defend the BCS position but, ultimately, had to concede defeat. It was turning into a Monty Python sketch that was getting too silly. However, the response has given me plenty of material that I can now use to further develop the debate back here. Consequently, over the next few days I will be posting a series of comments inspired by the ATTP nonsense and addressing a number of issues that come under the broad subject of ‘When Code Goes Wrong’. I shall start by discussing the importance of standards and why it isn’t clever to pretend you can do without them. Subjects I will cover in supplementary comments include:
Why would the BCS cite an article that says nothing about coding in order to support their view that professional standards in software development are required?
Should academics in ivory towers cite their lack of interest in what is going on in the real world as evidence that nothing of interest is going on in the real world?
Does the need to adapt a standard for application in a particular field count as evidence that the standard is irrelevant to that field?
Is Willard a real person or just a Bot that failed its validation testing?
Stay tuned.
LikeLiked by 1 person
The ATTP Debate Part 1: The importance of standards and why it isn’t clever to pretend you can do without them.
One of the most striking aspects of the response received over at ATTP following the posting of the BCS press release was the universal expression of disdain for professional standards in academic software development and those who might be calling for them. For example, there was this from Dhogaza:
“I’m guessing the BCS probably wrings their hands over this plague of software developed by uncertified practitioners not following BCS software development standards. And that the world of professional practitioners will, for the most part, continue to ignore them.”
Followed by:
“Not a shred of empirical evidence that following their [BCS] standards or employing people they’ve certified actually increases the quality of software products.”
And this from the ever sarcastic Willard:”
“So all we need is to apply standards to be developed. Should be done next week.”
And this from James Annan:
“Certification and charters aren’t the way to go.”
Then Steven Mosher weighs in with his take on the BCS report:
“It is a JOKE. and not even a funny one.”
Followed up with:
“Yes we need to audit the people calling for professional standards and make sure they followed professional standards in calling for professional standards. standards for thee not me.”
Then Willard, after quoting some derisive stuff about people who “spend most of their time inventing rules, creating forms that document whether everyone has followed the rules, filling in the forms, and assessing the content of the forms”, finally reaches the bottom of the barrel with:
“Another reason why standards are bureaucratic squirrels here is that coding, like language, is a social art.”
In a way, all of this doesn’t surprise me too much. Anyone such as I, who has tried to impose standards upon a software development community, let alone one steeped in the arrogant self-affirmation encountered within the corridors of academe, can tell you what a thankless task it can be – much like trying to herd a harem of preening cats. I think it is a cultural thing. There is a sense of ‘just leave me alone to do the thing I am best at and everything will be fine’. The more these creative and intelligent people are distracted by what they see as peripheral nonsense, the greater the resentment, accompanied by a kickback that is fueled by the suspicion that they are much cleverer and capable at doing what they do than are the people telling them they must do better. It’s all bureaucracy and red tape, don’t you know? It’s not what real programmers are interested in and it’s not what gets the job done. It just costs time and money that can be ill-afforded – and where is the proof that it does any good?
Well, it’s not as though I can be accused of lacking sympathy for such a view. Throughout my career in quality assurance and functional safety assurance there was not a day that went by when I didn’t find myself asking the question ‘what is this standard actually worth?’ In fact, that is precisely what I was paid to do. But any nuanced and tempered views I might have developed on the subject were not hewn from a sense of frustration and resentment; they were gained by examining the evidence and by developing professional relationships with the individuals that were responsible for the development of the standards concerned. See, for example, my CliScep article ‘Safety in Numbers’, in which I am hardly taking sides with bureaucracy:
https://cliscep.com/2018/03/31/safety-in-numbers/
But even when I was able to conclude that one should be very circumspect regarding the application of standards, I always remained aware of the reality of the situation. When it comes to ensuring the confidence of a client, whether it is justified or not, adherence to developmental standards was always a better strategy than flouting them. Indeed, in matters of safety certification, there would be no prospect of convincing anyone that failure to follow a required standard was acceptable. Although never the be-all-and-end-all, a significant factor in any safety case would be evidence of compliance with developmental standards.
So I say this to all the ATTP faithful who have such contempt for standards and chartered bodies. Just stop your whining and please understand that your disdain for the BCS and for ISO standards doesn’t amount to a hill of beans. The world of professionalism hears your cries and complaints but, no matter how sympathetic we may be, we are not actually paid to care. Present your self-assurance to the customer’s functional safety assessor and see how far it gets you.
In my next comment I will ask: “Why would the BCS cite an article that says nothing about coding, in order to support their view that professional standards in software development are required?”
LikeLiked by 1 person
John, it’s very interesting the way this debate has broken out at ATTP. Thanks for bringing back the details. I still have some things to say on it. The most important thing for me in the BCS proposal was insisting on open source for software that is going to be policy-influential. As for the rest, I’m mulling it over. I will come back to this. 🙂
LikeLike
The ATTP Debate Part 2: Why would the BCS cite an article that says nothing about coding, in order to support their view that professional standards in software development are required?
Another difficulty that attracted a lot of attention over at ATTP was the BCS’s citation of an article published in Nature to support their call for ‘professional standards in software development’. Well, I say ‘difficulty’ but this was only in the minds of those who didn’t seem to understand the difference between ‘software development’ and ‘coding’ and were unduly influenced by the number of times that the BCS press release used the words ‘code’ and ‘coding’. After all, ‘Computer coding’ was even in the title of the BCS article. Among those eager to point this out were Dikranmarsupial, Everett F Sargent and Steven Mosher. My insistence that, notwithstanding the use of such terminology, the press release was actually calling for ‘software development standards’ fell on deaf ears. As Everett said, “AFAIK C-O-D-I-N-G equals software development”. A view echoed by Dikran when he remarked, “LOL, hair thin distinction being made there”, although he contradicted himself later when he boasted that he well understood the important distinction:
“BTW I teach programming at undergraduate level. I know the difference between software development and so do the BCS, and coding was their term for it.”
Steven Mosher went so far as to claim, “John is redefining what they meant because they did not follow professional standards for CLEAR WRITING.” Yes, I know, this from the climate change debate’s most illiterate and incoherent English major.
I should pass over this misunderstanding quickly, because the mass ignorance of a group of individuals tripping out on confusion-induced testosterone shouldn’t be taken too seriously. However, it is a point worth following up, since the supposedly inappropriate citation of the Nature article was taken as evidence that the BCS was out of its depth (“the paper is a JOKE”, according to Mosher). Consequently, this is an allegation that has to be addressed. Dikran was perhaps the most vociferous in making the allegation, but Mosher summed it up when he said:
“In short. The “report” makes a call for “professional standards” in code development …and they cite as evidence for the need a nature paper THAT SAYS NOTHING about the software development process or code. The paper in question discusses other issues, unrelated to the actual dev process.”
Really? Well how about this to be found in the Nature article?
“Many machine-learning papers fail to perform an adequate set of experiments. Standards for review are inconsistent. And competition is encouraging some researchers to cut corners and skip checks once they think they have the answer they want.”
And what are these ‘experiments’ for, you might ask. The answer is, validation of the algorithms and the statistics underpinning the models. Is this anything to do with software development? Well, hell yes, when the algorithms are encoded in software designed to perform the statistics. And is validation of software part of the software development process? The answer, once again, is yes. It’s ensuring that the software is doing the right thing, which depends upon the requirements specification for the software being correct, which is difficult to prove with an inadequate ‘set of experiments’.
Dikran bemoans that the real problems are to do with statistics, not coding standards. He is of course correct. But he is wrong to conclude therefore that the validity of the statistics is not a matter of software validation, given that statistical analysis is such an integral part of what the software does. The point is that, when it comes to the validation of scientific software, the distinction between the software validation and scientific validation is immaterial; they are one and the same thing. Just because it isn’t a coding problem doesn’t mean that it isn’t a problem with the code.
So was a BCS press release that called for professional standards in software development justified in citing an article that highlighted shortcomings in the validation of models encoded in software? Yes, of course, unless you are following the lonely path of excluding validation from the definition of the development process. The point I would concede, however, is that the BCS citation of the Nature article did nothing to back up their concern that the scientific programmers were often not IT professionals. Software validation is as much a matter for the domain specialists as it is for the IT guys, if not more so.
In part 3 I will ask: What role do professional credentials play in safety validation and do BCS qualifications feature prominently?
LikeLike
Please John write very quietly, you don’t want to encourage the likes of Dikranmarsupial and Everett F Sargent to contaminate these Cliscep halls of eloquence and learning. Steven Mosher is just about (in)tolerable and comes in large doses.
LikeLiked by 1 person
I had an interaction with the intolerable Mosh on Twitter the other day. Well, I butted in to a chat he was having with the lovely Lucia (an important and irenic scientific blogger in the early days of Climate Audit) and we did I think establish an important area of agreement:
https://twitter.com/stevenmosher/status/1269051940861669376
The data and the code. The rest was good too I thought:
https://twitter.com/stevenmosher/status/1269061932205527040
https://twitter.com/stevenmosher/status/1269066347780030464
LikeLike
The ATTP Debate Part 3: What role do professional credentials play in safety validation and do BCS qualifications feature prominently?
So far I have concentrated on two of the most important areas requiring demonstration if one is to trust software used in applications that have public welfare and safety implications:
• Demonstration of adherence to recognized software development standards
• Demonstration of software validity.
I now turn to a third area of interest germane to the ATTP debate, namely demonstrating the competency of those involved in the software’s development.
Typically, if one is to construct an argument for competency, one would turn to an established competency management framework in which required competencies would be defined for all of the relevant duties and responsibilities involved. In IT applications, for example, one might use PROCOM or SFIA (or whatever else has been developed since I retired). However, where safety is an issue it would be more appropriate to use something like the IEE’s ‘Safety, Competency and Commitment – Competency Guidelines for Safety Related Systems Practitioners (ISBN 0 85296 787 X)’, as supported by the HSE and produced in collaboration with the BCS.
Given the BCS’s involvement in the development of the IEE guidelines, one might expect that they never miss an opportunity to call upon BCS membership as an essential demonstration of competency. After all, claims Dhogaza, the BCS is all about the promotion of their poxy qualifications that no serious practitioner is actually interested in:
“I’m guessing the BCS probably wrings their hands over this plague of software developed by uncertified practitioners not following BCS software development standards. And that the world of professional practitioners will, for the most part, continue to ignore them.”
Setting aside for the moment the non-existence of ‘BCS software development standards’, it is important to point out that in the IEE guidelines one finds no reference to required BCS membership or for the holding of any of its qualifications. The nearest one will find is a call for chartered engineer status for particular duties such as Independent Safety Assessor or Functional Safety Manager. That doesn’t mean that the IEE and BCS do not hold BCS qualifications in any regard. It just means that there is no need to refer to them explicitly. The expectation is that professionals who join chartered organizations such as the BCS do so because they are committed to professional self-development and are therefore more likely to have invested in the furtherance of those skills and experiences identified as relevant by the competency frameworks. Moreover, the development of professional portfolios place them in a better position to evidence such skills. It is such evidence that matters to competency frameworks and those who use them to perform competency assessments. If no objective evidence of such skills can be provided, then it’s tough-titty, with or without BCS membership.
Given that an objectively verifiable demonstration of practitioner competence is so important when developing a case for the use of software in safety-related applications, it is no wonder that a chartered institute such as the BCS should be concerned that academic software used in such applications so often involves personnel who lack the IT experience and qualifications found in a professional software development environment. The expression of their concerns should not have been controversial, and it reflects badly upon those who had to resort to ill-informed denigration of the BCS to deflect from a serious discussion of their concerns.
In the next part of my one-man debate, I will ask if academics in ivory towers should cite lack of interest in what is going on in the real world as evidence that nothing of interest is going on in the real world.
LikeLiked by 1 person
Good part 3 there John. However, while I admire your determination in soldiering on, I doubt you’ll be making much of an impact over at ATTP.
It’s a somewhat separate point, but it is also necessary that, while being appropriate and productive for say the BCS to contribute to IEE safety guidelines, many others also must and also sufficient distance between orgs has to be maintained to stop incestuousness developing. No doubt that’s the case here. Nearer the top of the safety tree for flight critical, where the number of involved parties tends to be somewhat distilled, it did bother me that the Designated Engineering Representatives (DERs), are both very significantly involved in assisting standards development (especially in respect of how to handle new technology), yet are also the ultimate authority in signing off on all flight safety systems. Further, DERs appear to form a kind of a small community of their own, many very well known to each other (and covering different angles). All of the highest motivation I add, but well, whether for company or consultant brands of DER (which seem also somewhat inter-changable), it did all strike me as a system in which incestuousness could creep in.
On a completely different note and reflecting Tony’s post, I shudder to think what will happen when the expanding wave of nonsense critical studies engulfs safety engineering. Maybe some areas will remain sacrosanct, but I can’t quite exclude from my mind the possibility of planes falling out of the sky because the original safety approaches were too colonialist or too white or too masculine or too trans-exclusive, or whatever.
LikeLiked by 1 person
Andy,
Thanks for that.
I would have to be quite the optimist to think I might be making any impression upon anyone. Sometimes it’s just a case of doing something for your own entertainment, and I am quite enjoying just laying down an argument without interruption. I have still got quite a bit more to say and if I am just talking to myself, that’s fine by me. In quality assurance one got quite used to talking to oneself.
Your warning about incestuous relationships and lack of independence is very valid. It’s something one always looked out for in safety cases. As for the woke version of safety validation, I trust that the personalities involved in the field would be the last to be swept up by such nonsense. I think the planes will not be falling out of the sky any time soon – I hope.
LikeLiked by 1 person
The ATTP Debate Part 4: Should academics in ivory towers cite lack of interest in what is going on in the real world as evidence that nothing of interest is going on in the real world?
A key ploy used in the debate over at ATTP, particularly by Dikranmarsupial, was the citing of credentials. As a machine learning specialist, he wasn’t going to concede to anyone who wasn’t one, even when the discussion point wasn’t just about machine learning. In particular, my claims that there was now considerable interest in the software development standards applied to machine learning software was rebuffed with:
“So much attention? Google scholar suggests otherwise, the most highly cited paper I could find was that one, with 42 citations, and a paucity of journal papers. That suggests there is a small commuity of researchers working on that topic. I’ve been going to machine learning conferences for decades, and there is rarely more than a special session about that sort of thin, if that. Give me a break!”
The problem with this argument, of course, is that it assumes that there is only one community of importance in the debate, i.e. the community of academic machine learning researchers. In actual fact, I was alluding to the interest shown within the functional safety engineering community, who are well aware of the lack of functional safety activity within the machine learning community and are very concerned about it. After all, it is the functional safety guys who will have to take the machine learning software and prove its safety in operation.
You will not be able to measure a level of concern for a lack of google scholar citations on a subject by counting the number of google citations on a subject. If, however, one were to leave the ivory towers of academia behind, and enter the real world of application, then the level of attention would quickly become very apparent. If you want to know about the real levels of attention, you need to stop going to machine learning conferences and start going to safety engineering conferences and then you will see what I meant. For example, one could have attended the 2020 annual SCSC conference in York, where the problems of validating the safety of autonomous software was the sole topic of conversation for 3 days. So I’m sorry, but I’m not going to accept that Dikran’s lack of interest in what is going on in the real world is evidence that there is nothing going on out there.
My reference to ISO 26262 was also germane because this is the adaption of the IEC 61508 standard that is used for systems development in the automotive industry, and if this standard is being modified to address problems with the software development standards applied in machine learning then you had better believe that the automotive industry thinks there is a problem. And the interest doesn’t end there. The problem is also recognized by the aviation industry:
Click to access SIDs_2017_paper_29.pdf
It is not surprising that the interest in software development standards is more prominent in industry than it is in the halls of academia in which academic research is performed. By the same token, it is not surprising that the safety implications of failing to adopt recognised software development standards are of greater interest to those who will suffer from the safety failings of epidemiological models than to those who use them for academic research.
In the next part of my extended rant I will be asking if safety-related software developed by academics must be exempted from the normal standards applied and, if so, what would be the implications.
LikeLiked by 2 people
John: What percentage of software developed by academics is safety-related software?
LikeLike
Richard,
I haven’t got a clue but I suspect it is very low. It is also worth keeping in mind that the BCS was only calling for that small category to be subjected to additional standards, not academic software in general. This is a topic I intend addressing in the next comment.
LikeLike
Glad to hear it!
LikeLike
John,
“I was alluding to the interest shown within the functional safety engineering community, who are well aware of the lack of functional safety activity within the machine learning community and are very concerned about it.”
A couple of years back I was peripherally involved with this, in respect of autonomous military vehicles. Western militaries are to some extent still being dragged kicking and screaming into what might be termed the ‘standard’ safety domain, i.e. out from under various military exceptions (military personnel being expendable and such). However, the case that this must happen has long been accepted, it’s more a case of delaying or phasing the implementations as much as possible in order to minimise spend plus impact on vehicle fleets / operations. Hence even some upgrades still avoid it, although all new programs pretty much forced to comply. The turning point was really when Mil aircraft were forced to prove safety standards in order to be able to share commercial airspace. Being nothing if not long-term planners and having to accept the inevitable, plus always recognising the functional up-side of technology advance in war theatres, some requirements shot the other way. I.e. from resisting, to massive embrace, you might say, and wanted autonomous technology also to comply to top-level safety, being prepared to throw money at the issue. While this is a big opportunity, one might say, it’s a massive challenge. Even the half-way house of diluting functionality to achieve ‘better’ safety, is a massive challenge. As far as I could tell, autonomous operation executed via machine-learning software algorithms on large multi-processor arrays to say DO-254 / 178, is pretty much a contradiction in terms. Currently, their requirements just contradict. The point being however, is that there is enormous interest in this topic, which also has direct overlap with commercial autonomous vehicles (to the extent that not only is technology leveraged, but actual staff hired from there too), and standards overlap likewise (albeit SIL D of ISO 26262 is less stringent than the DO-178C level A as far as I recall). In consequence, conferences for commercial autonomous vehicles, and Mil conferences generally, plus embedded electronics conferences generally too, all tend to have significant activity on this area, and often it’s one of the most attended topics, because it’s the ‘big problem to solve’. While indeed it’s still a minority topic at AI / machine-learning conferences, in recent years it’s climbed the agenda somewhat, because it is a significant barrier to much of the AI actually being deployed for the intended markets if it can’t be cracked. Another giant issue, on which this time the military appears to be leading, is how to combine all of the above with MILS level 7 security (mathematically provable), or at least 6+. While some requirements and technology for MILS and Safety operation are common (so both use strongly partitioned operating systems for instance, to prevent operation in one domain entering another), in practice the MILS thing introduces a whole other set of often contradicting (both with machine-learning architectures and safety architectures) requirements. Having leapt in some instances from largely ‘nothing’, to requiring ‘everything’ it was hard to break the reality to some accounts that ‘everything’ is still massively out of reach at this time. I mean even theoretically not just practically – albeit this doesn’t mean the right architectures can’t be laid down for phased evolution of systems towards the goal (a concept very familiar to military customers). Some OSs can in principle do the safe and secure thing together for a simpler (definitely not machine-learning) application, albeit the functional limitations and extra cost / timescales would probably cripple many projects if fully implemented. Putting this in an AI / machine-learning context still breaks everything. The military ‘FACE’ specification (it’s a public spec, no secrecy involved outside of draft versions) used for air vehicles, does indeed at it’s top level call for full safety and security and is applied to projects that will need machine-learning solutions. I seem to have blurbed rather on an area of past interest. However the main point is that there is immense interest and activity on these topics, and I can personally attest to significant spend from both mil projects and commercial suppliers to same using their own dollars to address it.
LikeLiked by 1 person
Andy,
Thanks. That was an excellent insight into the military perspective. I have no experience working to military standards but I am not in the least bit surprised to see that the problem of autonomous software is such a preoccupation there also, as indeed is the general drive towards addressing safety certification issues. Even in war, health & safety with its attendant risk of litigation casts its onerous shadow.
LikeLiked by 2 people
The ATTP debate part 5: Must safety-related software developed by academics be exempted from the normal standards applied and, if so, what would be the implications?
A central theme to the pleading over at ATTP was that academic software is a special case and, for good reason, cannot be required to meet the same standards as commercially developed software, let alone software developed to the high integrity required of safety-critical applications. The special pleading proceeds as follows: Firstly, it is normal that the only people who need to understand in detail how the software works are those who developed it. Secondly, there is usually no customer who is prepared to pay for the extra cost of development. And finally, the prolonged development timescales cannot be tolerated in an environment where the timely production of scientific results is so important. As Dhogaza summarised:
“It has already been explained over and over again why the requirements for software developed by researchers are different than the requirements of commercial software…”
Somebody calling themselves ‘Yeti’ was particularly keen to point out to me the cost problem (even though I had already remarked that cost is an issue when responding earlier to Ken Rice):
“The standards, when followed strictly, increase cost and time to your project by 2x – 5x depending on which level you follow. No one does this unless there is a very good reason to do it. Academics don’t do this, these standards are not created for academics.”
In fact, Yeti hits the nail on the head: No one follows standards required for safety-related applications unless there is a very good reason. And that reason is usually because safety certification is required as a protection against litigation. Given the implications of epidemiologic models being defective, there is surely a very good argument for such protection being required, and come the day that society settles upon that conclusion you will find that the funding required to do the job properly will suddenly become available. The bottom line is that no one who is motivated to sue is going to back off when they learn that the software concerned was developed to academic standards only, and so has to be excused because it is covered by ‘Dhogaza’s Law’.
Actually, Dhogaza seems to think this is all about forcing academics to inappropriately employ commercial standards ‘not created for academics’. Well, that isn’t really the point. When constructing a safety case there are two particular challenges that a functional safety manager will often encounter. The first is what to do when the system utilizes Commercial Of The Shelf (COTS) software. The problem here is that commercially available software is often built without safety standards in mind and so, even though commercial standards of development may have been followed, that may still not bestow the levels of confidence required for the proposed application. Secondly, there is the matter of Software of Unknown Provenance (SOUP), which may or may not be COTS. Here nothing is known about the development history of the software. This is where the situation becomes particularly problematic (I know because I have been that soldier). Basically, one has to take the software and scrutinize it until the cows come home (this is when Independent Safety Assessment (ISA) becomes a major issue). And guess what the most important thing is when one finds oneself in that situation – it’s access to the code. Given that so much academic software falls into the SOUP category (particularly given that academics insist on pleading poverty and beg special treatment) it is no wonder that the BCS should be calling for open access to code and data as a bare minimum. If academics want to operate in the risky world of safety-related software then they are either going to have to step up to the plate or accept that their contributions will forever be treated as SOUP subjected to ISA. There is no third alternative, despite Dhogaza’s pleadings.
Having said all of the above, there is one crumb of comfort. The BCS is not calling for all academic software to be improved, only that which is safety-related in its application. I trust that this is a relatively small percentage.
In the next part I will be asking: Does the need to adapt a standard for application in a particular field count as an example of that standard being irrelevant to that field?
LikeLike
John,
It’s not particularly germane to your part 5, but re your mention of COTS, I should have added that, below the actual application level s/w, all of the stuff above is accomplished by COTS s/w modules. Even the big military integrators or the military themselves, have very long since stopped making their own stuff, which is actually far more expensive and difficult to maintain plus keep up with the technology leaps, than simply using modern COTS. There’s a reasonable range of type 1 hypervisors, Real-time OSs (much of the above needs real-time control too), communication and other middlewares, even OpenGL graphics display modules, all available as standard DO-178 reusable software components (RSC). While always needing a new safety-case per equipment, one can import the same artifacts for each usage without having to regenerate them, via the FAA granted RSC exception for proven components. A small subset of these commercial offerings also support MILS for secure operation over levels from about 4 to 7.
LikeLiked by 1 person
Andy,
Thanks again. COTS is definitely the way to go when you can get it and it meets the spec!
LikeLiked by 1 person
The ATTP debate part 6: Does the need to adapt a standard for application in a particular field count as an example of that standard being irrelevant to that field?
This may strike you as a very odd question to ask since the answer is quite obviously ‘No’. When a standard is tailored to better fit the field within which it is intended to apply this is done so precisely because the intent is to apply the standard. However, this obvious point seems to be entirely lost on Steven Mosher, who had this to say when I introduced to the ATTP debate a paper discussing how ISO 26262 could be modified to better accommodate machine learning technology:
“John is not arguing that standards should be applied. The paper he cited argues the reverse. Standards should be changed. maybe he didn’t read it. we should apply comprehension standards.”
I would indeed require astronomically high standards of comprehension to understand how anyone could be so stupid as to think they were making a valid point here. Did Mosher honestly think he had caught me out failing to read a paper I had cited? Perhaps he had failed to notice how I had actually introduced the paper:
“Why would there be so much attention being paid towards adopting and adapting development lifecycles such as those advocated by ISO 26262?”
So yes, of course, when adopting a standard, adaption is often required. After all, ISO 26262 is itself an adaptation of IEC 61508. Adaptation doesn’t mean that the standards are not then expected to apply in their enhanced form.
Take, for example the Motor Industry Software Reliability Association (MISRA) coding standards for C and C++. These are a set of guidelines developed to help practitioners avoid some of the language features deemed to be non-conducive to the production of reliable software. Consequently, they are often called up as a requirement for safety-related applications (and not just within the automotive industry). I have experience of these standards because, as a member of the MISRA steering group, I sat in on some of MISRA’s technical meetings where the standards were being thrashed out. Back in my office, when the time came to use C++ on a safety-related project, I oversaw the adoption and adaption of those standards within my own company. Note that there are two levels of adaption here: Firstly from the definition of the C++ language to MISRA C++. Secondly from MISRA C++ to the particular variant I developed for use by my own employer. In those days, the second level of adaption meant that MISRA compliance could not then be claimed. Nowadays, MISRA C++ has been evolved so that practitioner tailoring is not only allowed, it is actively encouraged.
I like to think that, over the years, I developed a somewhat well-informed view of standards, what they are good for, their limitations and where they fit into the broader objective of ensuring the cost-effective development of reliable systems. I certainly don’t consider, therefore, that I have any need to respect Steven Mosher’s parting shot:
“I think we all have some sympathy for the need for standards of sorts when it comes to
policy relevant code— lets expand that to “Systems” to capture all the aspects of model creation, that might better capture all the issues: data, config files, code, tests, verification, validation, reports, documentation… blah blah blah. obviously no one is arguing for total chaos in the development of systems, and also no one ( except maybe John) thinks that standards/processes create greatness ex nihilo.”
Mosher really has no excuse for being so ignorant of my views. They were posted on this site over two years ago:
https://cliscep.com/2018/03/31/safety-in-numbers/
In the final part of my rant, I will list all the further topics that require discussion when considering the software development lifecycle within the context of safety-related applications. However, you can relax, safe in the knowledge that I don’t intend expanding upon any of them.
LikeLiked by 1 person
On second thoughts, I think I’ll leave it there now. This is getting too much like hard work and I suddenly remembered I don’t get paid for this sort of thing anymore.
LikeLiked by 1 person
“After all, ISO 26262 is itself an adaptation of IEC 61508. ”
Actually, I don’t think I know of any standards that are not to some extent adaptations from previous. Even ‘brand-new’ ones, of which one or two I’ve been involved with and others I’m familiar with the history / creation process, seem always to be constructed out of appropriate parts and principles from either adjacent areas, or are generic fundamentals that need their expression tailored to fit.
LikeLiked by 1 person
Liking the comment where you say you’re going to leave it is not to be taken as lack of appreciation for the long ones that preceded it John! (Or Andy’s comments on the challenges for military software developers.)
Forgive me if this basic question betrays the fact that I haven’t read all the other words as carefully as I might but do you and the BCS consider Neil Ferguson’s code safety-related? Or, perhaps more realistically, that it should have been classified as such, with the beautiful benefit of hindsight?
LikeLiked by 1 person
Richard,
The BCS (deliberately?) did not use the term ‘safety-related’ but they did refer to models used to inform policy that had public welfare and safety implications. This, in my view, makes them safety-related since their reliability and integrity has a safety importance. The problem is that some of the software concerned is developed for research purposes and only takes on a safety importance when the science starts to inform the political decision-making. Can research scientists be expected to second guess the purpose to which their research software may be put? The BCS seems to think so in at least some circumstances. And even if they can’t, then there is no reason why some retrospective assessent of the code could not be made as part of the process of policy application. In a sense this is what is happening, albeit unofficially and too late in the day.
LikeLiked by 1 person
“And even if they can’t, then there is no reason why some retrospective assessent of the code could not be made as part of the process of policy application. In a sense this is what is happening, albeit unofficially and too late in the day.”
Indeed too late. Part of what we should learn for this, as part of preparedness, is that while anything may go for purely research purposes, only s/w that is compliant to appropriate process / standards should be used for significant (and especially any life / death) policy assistance. Which implies constant promotion of models from one domain to the other (even if a complete re-write required), otherwise they will never be available in time when they *are* needed. Given research budgets (not to mention the interest of the researchers) is unlikely to cover this angle, funding and execution (for instance by hiring commercial skills) should be applied as part of social protection, via the same sort of budgets as other contingency planning, such as for instance the stockpiling of PPE or ensuring enough facilities (likely in conjunction with private enterprise for volume / diversity) to manufacture sufficient vaccines within the UK for UK consumption.
LikeLike
Andy,
Agreed. One of the most astonishing things about the ATTP debate is that the BCS included climate models in their list, and yet no one remarked about that.
Climate models, indeed. Now we really are talking SOUP!
LikeLiked by 1 person
“Climate models, indeed. Now we really are talking SOUP!”
Like Minestrone, but hotter, more Catastrone maybe.
LikeLiked by 1 person
John: Helpful and fair summary, thanks, including that factlet about climate models. (Perhaps that was spotted by some bright sparks at ATTP and explains their preemptive mockery of the BCS, without of course drawing attention to the reason.) I have conflicting thoughts on the whole shebang now, which is not unusual. An anecdote will arrive in short order. Only two academic coders have a role within it, plus yours truly. As far as the money made goes, I was in the middle. But it was pretty handy..
LikeLiked by 1 person
Richard,
The climate modelling situation is more difficult to defend, I feel. From very early on, the research was undertaken with more than just academic interest at heart. It was funded and supported as an area of research that had huge significance to public welfare and safety. Getting it wrong could cost millions of lives, so we are told. And yet the software development was undertaken with less quality control than you would expect for a toaster. Of course, getting the science right is paramount, but more software quality assurance wouldn’t have gone amiss.
Also, the mockery of the BCS struck me as a bit ironic given how quickly disrespect for organisations such as the IPCC is dismissed as denialism.
LikeLiked by 3 people
Richard,
Actually, the denialism on parade over at ATTP will have to extend beyond denigration of the BCS if the following section of the BCS press release is to be addressed:
“Given the seriousness of this issue and the significant consequences of not using relevant best practice and specialists, BCS will approach experts across the sector to discuss how to professionalise software development practice in scientific research including the Centre for Data Ethics and Innovation, the Alan Turing Institute, the Safety Critical Systems club, the British Insurance Association, Royal Society, the Royal Academy of Engineering, Cabinet Office, NHSX, UKRI, Public Health England.”
That would be quite a lot of interest for Dikran to overlook with his google scholar searches. In reality, I think the ATTP crew are going to need a bigger boat.
Andy,
Just to underline a point made in one of your earlier comments, there is also this in the BCS press release:
“According to BCS, professionalising and using best practice software development in scientific research should lead to… the ability of scientists to correctly modify software implementations of computational models in times of crisis as rapidly as possible.”
LikeLiked by 2 people
Wow to that list of orgs. As long as we don’t lose sight of the second V of V&V. (I think I mean the second one. Help needed at that most basic terminological level. Chris Essex’s critique of the GCMs is all about the computational impossibilities given what we know of Navier-Stokes, grid size and all the rest.)
LikeLike
Richard,
I quickly learnt not to lose too many nights sleep over the distinction between verification and validation. It struck me as one of those examples where perfectly well-defined words were being co-opted into jargon, first by giving them capital letters and then by combining them into a slogan (V&V). Verification is supposed to be about doing something the right way, and Validation is supposed to be about doing the right thing. However, this is not what you can learn from consulting a dictionary. ‘Verification’ is exactly what the word implies – the determination of veracity or truth. For example, one may ask if the design specification is true to the requirements specification, or whether the code is true to the design specification, etc. ‘Validation’, as the word implies, is about determining validity or value – yet invariably as a result of a verification.
Experts, who are paid a lot of money to tell you things, will tell you that Verification and Validation activities are not to be confused; however, in practice, most activities can be labelled as both, i.e. many acts of verification have the effect of determining validity and no act of validation can take place without verifying something.
In short, I have never been impressed with the official definition for V&V because the two Vs are defined as mutually exclusive activities when, as far as the dictionary is concerned, they are most-often attendant, albeit distinct, purposes.
The fact is that ‘Validation’ with the capital ‘V’ is just a special case of verification in which veracity relating to the requirements specification is involved (presupposing, of course, that the requirements specification itself properly captured the customer’s needs. If what the customer said they wanted differs from what the customer actually needed, you are on a sticky wicket, but that’s what maintenance contracts are for).
LikeLiked by 1 person
That feels like therapy as much as education John. I used the term “Maximum verification” as one of the “Seven Pillars of CRED” (Controlled Rapid Evolutionary Delivery) when Ed Yourdon asked me to summarise Objective’s development philosophy (Objective being the company I’d co-founded in 1983) in the mid 90s. I don’t even remember how Ed got to hear of us but he published my piece in his magazine without quibbling over that terminology. We were already using the term agile for the way we thought software ought to be but it wasn’t in wider circulation at that point. (The Agile Manifesto in 2001 would be the main jump-off point for that buzzword.) It’s only more recently that I’ve wondered if I should have been making this V/V distinction. I won’t be losing more sleep over it. Thanks.
(And only now I see from Wikipedia that Ed died in 2016, aged 71. Stay well, all my Cliscep friends.)
LikeLiked by 1 person
When I look back at my last comment I find it embarrassingly wordy. I could have just said that if you want to know the difference between verification and validation you should just consult a dictionary. But if you want to know the difference between Verification and Validation you will have to ask a consultant. The world will never have enough consultants.
Speaking of therapy, I used to have nightmares in which I was being chased down a busy high-street by the capital letter ‘V’, before noticing I was naked from the waist down. But then I’d discover ‘agile’ and in one bound I would be free. What did that mean?
LikeLiked by 1 person
Cyber Deference, tee hee. Serfs sadly ignorant of code but less so of human naychur naturally susspicious of models https://beththeserf.wordpress.com/2018/12/23/56th-edition-serf-under_ground-journal/ old stuff here but good stuff, Professor Linzen et al, (not Big AL) re bringing data into agreement with models.
LikeLiked by 1 person
Beth: I will read that, thank you. You’re absolutely right not to be bamboozled by code or coders but to trust your judgment of human nature – and to listen to Richard Lindzen. The one time I had the chance to talk to him, after a Parliamentary Select Committee had been questioning Donna Laframboise, Nic Lewis and himself (in a deeply stupid manner) I managed to say thank you for everything he’s done – since around 1988 – without actually bowing! In response he told me a joke or two. I almost said Jewish joke there as it seemed typical deflection, yet wih appreciation for what I’d said. One doesn’t always take those chances.
LikeLike
You talked to Richard Lindzen! )
LikeLiked by 1 person
Beth. That’s nothing, I stayed away from a talk by Michael Mann.
LikeLiked by 1 person
Beth: I did. And lived to tell the tale.
LikeLike
Richard and Alan , lol, At a talk at th Institute of Public Affairs, Melbourne Oz I got to ask a question to Matt Ridley and Bjorn Lomberg!
LikeLiked by 1 person
I don’t have time to discuss it atm but Michael Veale is doing open source coding of mobile apps to support ‘test, track and trace’ – for Switzerland I think, with links to similar efforts for Germany. I have to say I feel he made the right call in April – though it pains me to see the power of Apple to dictate to governments.
And, as we’ve said right from the start, it’s not primarily the quality of the code that is make or break but the design, including in this case that of the UX (user experience). Veale seemed on track with that aspect, not overstating the importance of tech, when I watched the full panel discussion on Newsnight last night.
LikeLike