One of the central ideas underpinning climate change projection is that of the climate model ensemble. The thinking behind an ensemble is very simple. If one takes a number of models, each of which cannot be assumed to be a faithful and complete representation of the system being modelled, then the average of their projections is likely to be closer to the truth than any single one. Furthermore, the spread of projections can be used to represent the uncertainty associated with that average. This entails a well-established statistical approach in which the spread is assumed to take the form of a probability density function.
However, nobody should underestimate the difficulties to be overcome by the climate modellers, since the models concerned will be subject to a number of parametric and structural uncertainties. Furthermore, the tuning of the models, and the basis for their inclusion and weighting within the ensemble, can be more of a black art than a science. Despite this, it is assumed that the resulting uncertainties are nevertheless captured by the properties of the probability distribution. The purpose of this article is to convince you that the problems are too deep-seated for that to be the case, since the uncertainties can actually invalidate the statistical methodology employed to analyse the ensemble. In reality, the distribution of projections is highly unlikely to form a true probability density function and so should not be treated as such.
To make my case I will be dividing my argument into two parts. In the first, I will introduce some basics of uncertainty analysis and explain how their consideration has led to the development of guidelines for the handling of uncertainty in system modelling. There will be no reference to climate science in this first part since the guidelines have general application. In the second part, I will examine the extent to which the guidelines have been embraced by the climate science community and explain the implications for evaluation of climate model ensembles. Finally, having made my case, I will briefly discuss the origins and significance of the climate science community’s mishandling of uncertainty analysis and what this may mean for the validity of climate change policy. The central premise is that no policy, least of all one associated with something as hugely important as climate change management, should be based upon the misapplication of statistical technique.
The background issues
Fundamental to an understanding of uncertainty is the ability to answer the following question: Does the uncertainty regarding the likely future state of a system have as its basis the inherent variability of that system, or is it due to gaps in our understanding of the causation behind the variability? To the extent that variability by itself can lead to uncertainty, one will be in the province of stochastic physics. Here the mathematics of randomness will apply, with the caveat that one may be dealing with a chaotic system in which the randomness stems from deterministic processes that are critically sensitive to boundary conditions. If the processes involved are fully understood, and the boundary conditions have been quantified with maximum precision, then the residual uncertainty will be both objective and irreducible. Such uncertainty is sometimes known as aleatory uncertainty, from the Latin for a gambler’s die, alea.1
In practice, however, the basis for the variability may not be fully understood. These gaps in knowledge lead to a fundamentally different form of uncertainty called epistemic uncertainty. Such uncertainty is subjective, since different parties may have differing perspectives that bear upon their understanding of the variability. It can be reduced simply by filling the gaps in knowledge. As a side-effect of the reduction of epistemic uncertainty, a consensus will emerge. However, care has to be taken when using consensus as a metric to measure levels of epistemic uncertainty, since there are also non-epistemic processes that can lead to the development of consensus.2
A simple example that can be used to illustrate the distinction between aleatory and epistemic uncertainty would be a system in which variability results from the random outcome of a thrown die. For a die of a known number of sides, the average score over time is determined by well-understood probability theory and it is a simple matter to determine the appropriate probability distribution. Furthermore, the uncertainty of outcome is both objective and irreducible – it is, after all, the titular aleatory uncertainty. However, now consider a situation in which the number of sides of the die is unknown. In this example the range of possibilities for the average score over time is greater, and there is both an epistemic and aleatory component to the uncertainty. It remains the case that the aleatory component can be defined using a probability density function but the same cannot be said of the epistemic component since it represents an entirely deterministic situation (i.e. it is a fixed number that is simply unknown). A set of probabilities can be provided representing the likelihoods for the various possible number of sides, but there can be no guarantee that the full state space is represented by such a set and there is no basis for assuming that stochastic logic applies to their allocation (as it would for the aleatory). For that reason the amalgamation of the epistemic and aleatory uncertainties cannot be represented by a true probability density function, or at the very least, such a function would not be as meaningful as that used for the aleatory component on its own.
You will also note that in both situations the likelihood (i.e. for the average score of the known die, and for the number of sides of the unknown die) has been characterised by the allocation of probabilities. This is a fundamental difficulty that lies at the heart of uncertainty analysis since probability has such a dual purpose of quantifying both variability and incertitude (between which it does not discern). Consequently, any mathematical technique for analysing uncertainty that is basically probabilistic will suffer from the same drawback, i.e. it runs the risk of conflating variability and incertitude. Yet, as I have just pointed out, only the former lends itself to a stochastically determined probability distribution. It is highly likely, therefore, that the application of such a probabilistic technique will lead to erroneous results if the epistemic and aleatory components have not been isolated prior to the positing of a probability distribution representing the overall uncertainty. As Professors Armen Der Kiureghian and Ove Ditlevsen have noted in the context of time-variant, structural reliability modelling:
The distinction between aleatory and epistemic uncertainties is determined by our modeling choices. The distinction is useful for identifying sources of uncertainty that can be reduced, and in developing sound risk and reliability models. It is shown that for proper formulation of reliability, careful attention should be paid to the categorization (epistemic, aleatory, ergodic or non-ergodic) of uncertainties. Failure to do so may result in underestimation or overestimation of failure probability, which can be quite significant (orders of magnitude) in certain cases.
‘Aleatory or epistemic? Does it matter?’, 2007
In real life, most systems are a lot more complicated than the throwing of a single n-sided die. Typically, a system’s mathematical model will have many free variables (i.e. parameters and boundary conditions) of uncertain value that will determine any projection based upon it. To handle this complexity, modellers employ a technique referred to as Monte Carlo simulation in which multiple runs of the model are aggregated to create a statistical spread of projections. Each run is based upon a random sampling of the possible parametric or boundary condition values allowed for by the model. When performing the sampling, the likelihood of selecting any particular value for a given variable is determined by the probability distribution that applies to that variable’s uncertainty. Note, however, that I used the term ‘random sampling’ here. This is because Monte Carlo simulation is a technique originally developed for the analysis of aleatory uncertainty (it finds widespread use in the field of stochastic physics). When the variable’s uncertainty is epistemic, however, random sampling is inappropriate because the actual value is subject to deterministic incertitude and not stochastic variability. For such variables, one would be sampling possible opinions of experts rather than variable states of the system. But Monte Carlo simulation doesn’t care. Give it a set of probabilities expressing a variable’s uncertainty and it will crunch those numbers merrily and provide you with a very aleatoric looking output. That doesn’t mean that it can be relied upon, however.
The restrictions on the applicability of Monte Carlo simulation are well-known and have led to written guidelines to be followed by mathematical modellers working within the field of risk assessment. Here, for example, is how the US Environmental Protection Agency (EPA) has put it:
Monte Carlo simulation also has important limitations, which have restrained EPA from accepting it as a preferred risk assessment tool. Available software cannot distinguish between variability and uncertainty. Some factors, such as body weight and tap water ingestion, show well-described differences among individuals. These differences are called ‘variability’. Other factors, such as frequency and duration of trespassing, are simply unknown. This lack of knowledge is called ‘uncertainty’.3 Current Monte Carlo software treats uncertainty as if it were variability, which may produce misleading results.
‘Use of Monte Carlo simulation in risk assessments’, 1994
And here is what Professor Susan R. Poulter has to say regarding the guidelines issued by the US National Academy of Sciences (NAS):
In ‘Science and Judgment in Risk Assessment’, the NAS noted the problems with incorporation of subjective assessments of model uncertainty into probability distribution functions, suggesting that such quantitative analyses of model uncertainty be reserved for priority setting and risk trading. For standard setting, residual risk determinations and risk communication, however, the NAS recommended that separate analyses of parameter uncertainty be conducted for each relevant model (rather than a single hybrid distribution), with additional reporting of the subjective probability that each model is correct.4
‘Monte Carlo simulation in environmental risk assessment –Science, policy and legal issues’, 1998
None of this is to say that Monte Carlo simulation is a bad idea or a technique that should never be used. On the contrary, it can be an invaluable tool when analysing the effects of variability in essentially stochastic systems. The problems only emerge when epistemic uncertainty features in the system’s mathematical model and this is not properly isolated, and allowed for, when assessing the extent to which the probability distributions produced by the simulation fully capture the uncertainty.
So, the key questions are these: Is there any indication that these issues and the guidelines arising have been taken on board by the climate scientists? Have they understood that ensemble statistics can be inappropriate or very misleading when epistemic uncertainties are present? And if they haven’t, can we trust the uncertainties they attribute to climate model projections, particularly when model ensembles are involved?
The relevance to climate science
In fact, there is plenty of evidence that the issues are familiar to the community of climate modellers. For example, there is the following from Professor Jeroen Pieter van der Sluijs, of the University of Bergen, regarding the uncertainties associated with climate sensitivity:
Being the product of deterministic models, the 1.5°C to 4.5°C range is not a probability distribution. There have, nevertheless, been attempts to provide a ’best guess’ from the range. This has been regarded as a further useful simplification for policy-makers. However, non-specialists – such as policy-makers, journalists and other scientists – may have interpreted the range of climate sensitivity values as a virtual simulacrum of a probability distribution, the ’best guess’ becoming the ’most likely’ value.
‘Anchoring amid uncertainty’, 1997
The above quote makes it clear that the problem may not lie with the modellers but how various stakeholders and pundits choose to simplify the situation and read into it a scientific rigour that simply is not there. A similar point is made by Gavin Schmidt, climate modeller and Director of the NASA Goddard Institute for Space Studies (GISS) in New York:
Collections of the data from the different groups, called multi-model ensembles, have some interesting properties. Most notably the average of all the models is frequently closer to the observations than any individual model. But does this mean that the average of all the model projections into the future is in fact the best projection? And does the variability in the model projections truly measure the uncertainty? These are unanswerable questions.
‘Climate models produce projections, not probabilities’, 2007
Actually, the questions are not unanswerable, and the answer is ‘no’. It is Schmidt himself who provides the reasons when he goes on to say:
Model agreements (or spreads) are therefore not equivalent to probability statements. Since we cannot hope to span the full range of possible models (including all possible parameterizations) or to assess the uncertainty of physics about which we so far have no knowledge, hope that any ensemble range can ever be used as a surrogate for a full probability density function of future climate is futile.
As with Professor van der Sluijs, Schmidt implies that the pressure to ignore the issue comes from outside the community of climate modellers. Schmidt continues:
Yet demands from policy makers for scientific-looking probability distributions for regional climate changes are mounting, and while there are a number of ways to provide them, all, in my opinion, are equally unverifiable. Therefore, while it is seductive to attempt to corner our ignorance with the seeming certainty of 95-percent confidence intervals, the comfort it gives is likely to be an illusion.
Professor Eric Winsberg of the University of South Florida, a philosopher who specialises in the treatment of uncertainty in mathematical models, could not have made the problem with climate model ensembles any clearer when he said:
Ensemble methods assume that, in some relevant respect, the set of available models represent something like a sample of independent draws from the space of possible model structures. This is surely the greatest problem with ensemble statistical methods. The average and standard deviation of a set of trials is only meaningful if those trials represent a random sample of independent draws from the relevant space—in this case the space of possible model structures. Many commentators have noted that this assumption is not met by the set of climate models on the market…Perhaps we are meant to assume, instead, that the existing models are randomly distributed around the ideal model, in some kind of normal distribution, on analogy to measurement theory. But modeling isn’t measurement, and so there is very little reason to think this assumption holds.
‘Values and uncertainties in the predictions of global climate models’, 2012
This quote alludes to a problem that goes well beyond that of basic Monte Carlo simulation and its applicability. The ensembles to which Winsberg refers are not just ensembles of models in which differing parameters and boundary values are sampled from the range of possibilities — they are models that do not even have the same structure! To put this state space problem in perspective, consider the following quote from Professor Ken Carslaw:
But when it comes to understanding and reducing uncertainty, we need to bear in mind that a typical set of, say, 15 tuned models is essentially like selecting 15 points from our million-cornered space, except now we have 15 hopefully overlapping, million-cornered spaces to select from.
‘Climate models are uncertain, but we can do something about it’, 2018
If that does not invalidate the interpretation of the ensemble output as a probability density function, then I do not know what could.5
And yet, despite the guidance provided by the likes of the EPA and NAS, and despite the fact that the problem is known even to the climate modelling community, the practice of treating the spread of outputs from a climate model ensemble as if it were a probability density function resulting from a measurement exercise is widespread and firmly established. It seems the “demands from policy makers for scientific-looking probability distributions” have been enthusiastically fulfilled by those who should, and quite possibly do, know better. Take for example, the following figure to be found in the IPCC’s AR5, WG1, ‘The Physical Science Basis’:
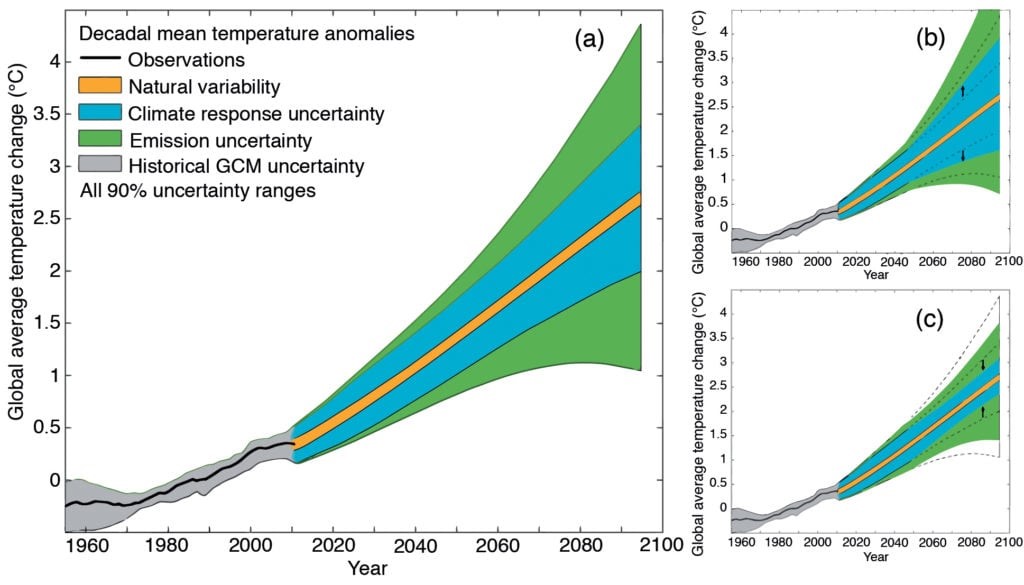
Note that both variability and uncertainty are treated equivalently here, as are the uncertainties relating to historical records and model-based projections. Furthermore, the claim regarding the portrayal of ‘90% uncertainty ranges’ indicates that everything is being treated as a probability distribution that adequately captures and quantifies the uncertainty. Also note that this is a diagram that appears in the report’s introduction and so serves the political purpose that was once the reserve of the hockey stick graph. As an eye-catching graphic, it is very successful. As a scientific representation of uncertainty, it falls well short. It does indeed appear that the policy makers have got what they wanted – a scientific-looking portrayal of uncertainty that appeals to their schoolday training in statistics.
Origins and implications
To fully appreciate what is going on here one has to understand that the idea of climate modelling and the use of model ensembles has its genesis in stochastic physics and the pioneering work of the likes of Suki Manabe (recent recipient of the Nobel Prize) and Professor Tim Palmer, Royal Society Research Professor in the Department of Physics, Oxford University, and author of the recently published ‘The Primacy of Doubt’. Both are pre-eminent in their field, both are experts in physical variability (Palmer explains that an alternative book title he had considered was ‘The Geometry of Chaos’). Yet neither has shown any signs of acknowledging that not every uncertainty in life can be characterised by a probability density function.
In his book, Palmer explains at some length the physical and mathematical basis for our climate’s variability and how it can be modelled, but not once does he mention the words ‘epistemic’ or ‘aleatory’ in the context of model uncertainty.6 He also sets out how Monte Carlo simulation can be used to analyse climate model ensembles, but not once does he acknowledge its limitations or refer to any of the published guidelines for its applicability. And then, on page 121, he reproduces a histogram7 illustrating the numbers of climate models that are predicting the various possible values for climate sensitivity (ECS), and for good measure he superimposes a probability density function to make clear the uncertainty indicated by the histogram! Why would a brilliant physicist commit such a basic gaffe? Why would he resort to an aleatoric representation of epistemic uncertainty?
Well, maybe because he actually is a brilliant physicist and not an expert in uncertainty analysis. He knows so much about the mathematics of stochastic physics and how it affects climate variability that he just couldn’t resist reaching for an aleatoric representation. It would have seemed to him the most natural thing to do.
And herein lies the rub. It isn’t just the policy makers and their demands for simplistic and familiar representations of uncertainty that are to blame. In many instances it is the scientists themselves who are making the mistake. And who is going to challenge someone such as Professor Palmer – someone who can lay claim to having turned down an offer to work alongside Stephen Hawking? When he suggests in his book that it is always okay to calculate probabilities by counting the numbers of climate models making a particular prediction and then divide by the total number of models, you have a seemingly massive expert authority to challenge. Yes, he is a brilliant scientist, but does that mean he is fully conversant with the philosophy of uncertainty and how it bears upon the validity of methodology?8
Palmer makes a very good point in his book: It is vital that in matters such as climate change that the uncertainties are not underplayed or overplayed. Unfortunately, however, underplaying the uncertainty is exactly what he does when he presents figures such as that on page 121. He superimposes a probability density function to portray the uncertainty but he fails to acknowledge that such a curve can only be a simulacrum of a probability distribution. It couldn’t be otherwise, because it doesn’t come anywhere close to reflecting the epistemic uncertainties affecting the models and the process of selection for the ensemble.
An understated uncertainty, of course, contributes to the narrative that the science is settled, and a settled science is what the policy makers demand. Scientists who treat everything as though the uncertainty is physically inherent rather than characteristic of gaps in their own knowledge are either wittingly or unwittingly playing into the hands of those who think that objectivity is what the science is all about. How this bears upon policy is very much a matter of how one views the importance of uncertainty. Those who would advocate the precautionary principle would argue that knowing the uncertainty has been understated is all the more reason for drastic action. Those who advocate that risk-based decisions should not be made when the uncertainty is high would argue that knowing the uncertainty has been understated is all the more reason instead to employ Robust Decision Making (RDM); in which case, a multi-trillion dollar commitment founded on a 15-point sample of a ‘million-cornered state space’ might not seem such a bright idea. All I will say is that an uncertainty analysis cannot possibly benefit from the misapplication of statistical technique, and so I tend to view the IPCC’s quantification of climate model ensemble uncertainties with a very healthy dose of empirical scepticism.
As a final word of warning, the fact that the uncertainty has been underestimated doesn’t automatically mean that the spread of projections is too narrow; it simply means that no reliable conclusion can be drawn from it because no probabilities can be inferred. This is not a view shared by the majority of climate scientists, however. Climate model ensembles are here to stay, and the illusion of objectivity that a probability density function gives the scientists goes hand in hand with the misconception that they can be certain how uncertain they are.
Notes:
[1] Hence the phrase attributed to Julius Caesar when crossing the Rubicon, ‘alea iacta est’, meaning ‘the die is cast’.
[2] This problem is discussed further in my article ‘The Confidence of Living in the Matrix’.
[3] Note that the EPA uses the term ‘uncertainty’ for ‘incertitude’. They are actually referring to epistemic uncertainty as opposed to aleatory uncertainty (i.e. variability).
[4] That said, the NAS is quite critical of the way in which the EPA analyses risk, accusing it of being too qualitative in its approach. On the other hand, in its own devotion to quantification, the NAS quite happily advocates the combination of subjective and objective probability into a hybrid distribution using Monte Carlo simulation, albeit for limited purposes. The obvious drawbacks of this are treated as acceptable and manageable difficulties.
[5] The distinction being made here is between two basic types of ensemble. The first (the Perturbed Physics Ensemble) is not as problematic as the second (the Multi-Model Ensemble).
[6] He does, however, use the term ‘epistemic uncertainty’ in the context of quantum mechanics when he refers to the debate as to whether quantum uncertainty is subjective or inherent. This is, of course, the famous Einstein/Bohr debate that was resolved with Alain Aspect’s experimental confirmation of the violation of Bell’s Inequality. Interestingly, Palmer does not use the term ‘aleatory’ anywhere, despite Einstein’s famous quote about God not playing dice.
[7] My apologies for not being able to reproduce the figure in my own article.
[8] If Professor Palmer does understand that there is a distinction to be made between incertitude and variability, he doesn’t seem to make much of it. The most revealing passage in his book is an attempt to explain what is meant by predicting an 80% probability for a future weather event. Amongst other things, he stresses that it does not mean that 80% of weather forecast providers think that the event will happen. And yet when it comes to the climate modellers’ multi-model ensembles, the calculus of consensus is very much the order of the day! Ignoring this, Palmer offers a purely frequentist interpretation of the probability, suggesting that he really does believe that modelling is measurement.
Referenced material and further reading
Distinguishing two dimensions of uncertainty, Craig R. Fox and Gulden Ulkiimen, Perspectives on Thinking, Judging, and Decision Making, Oslo, Norway: Universitetsforlaget, 2011.
Uncertainty Management in Reliability/Safety Assessment. In: Reliability and Safety Engineering. Springer Series in Reliability Engineering, vol 0. Springer, London. https://doi.org/10.1007/978-1-84996-232-2_11
Different methods are needed to propagate ignorance and variability, Scott Ferson and Lev R. Ginzburg, Reliability Engineering and System Safety 54, 1996.
Aleatory or epistemic? Does it matter?, Armen Der Kiureghian and Ove Ditlevsen, Special Workshop on Risk Acceptance and Risk Communication, March 26-27, 2007, Stanford University.
Understanding aleatory and epistemic parameter uncertainty in statistical models, N.W. Porter and V. A. Mousseau, Best Estimate Plus Uncertainty (BEPU) International Conference, 2020.
The role of epistemic uncertainty in risk analysis, Didier Dubois, Lecture Notes in Computer Science, LNAI Volume 6379.
What Monte Carlo Methods cannot do, Scott Ferson, Human and Ecological Risk Assessment, Volume 2, 1996 – Issue 4.
Use of Monte Carlo simulation in risk assessments, Region 3 Technical Guidance Manual, risk assessment, Roy L. Smith, 1994.
Guiding principles for Monte Carlo Analysis, EPA/630/R-97/001, March 1997.
Science Policy Council Handbook: Risk Characterization EPA Office of Science Policy, Office of Research and Development, EPA 100-B-00-002, 2000.
Monte Carlo simulation in environmental risk assessment – Science, policy and legal issues, Susan R. Poulter, Risk: Health, Safety and Environment, Volume 9 Number 1 Article 4, 1998.
Science and judgement in risk assessment: Chapter 9 Uncertainty, National Academies Press, 1994.
Uncertainty analysis methods, S. Mahadevan and S. Sarkar, Consortium for Risk Evaluation, 2009.
Anchoring amid uncertainty, Jeroen Pieter van der Sluijs, 1997.
Climate models produce projections, not probabilities, Gavin Schmidt, Bulletin of the Atomic Scientists, 2007.
Values and uncertainties in the predictions of global climate models, Eric Winsberg, Kennedy Institute of Ethics Journal, Volume 22, Number 2, June 2012.
Climate models are uncertain, but we can do something about it, K.S. Carslaw et al, Eos.org, 2018.
‘The Primacy of Doubt: From Quantum Physics to Climate Change, How the Science of Uncertainty Can Help Us Understand Our Chaotic World’, Tim Palmer, ISBN-10: 1541619714, 2022.
Uncertainty in regional climate modelling: A review, A. M. Foley, National University of Ireland, Maynooth, Republic of Ireland, Progress in Physical Geography 34(5) 647–670, 2010.
Statistical analysis in climate research: Introduction, Hans von Storch and Francis W. Zwiers, Cambridge University Press, 1999.
Multi-model ensembles in climate science: mathematical structures and expert judgements, Julie Jebeile and Michel Crucifix, Studies in History and Philosophy of Science Part A, 2020.
An antidote for hawkmoths: On the prevalence of structural chaos in non-linear modeling, Lukas Nabergall et al, August 2018.
The art and science of climate model tuning, Frederic Hourdin et al, Bulletin of the American Metreological Society, Volume 98, Issue 3.
Evaluation, characterization and communication of uncertainty by the Intergovernmental Panel on Climate Change – An introductory essay, Gary Yohe, Climatic Change, 2011.
Robust Decision Making, Wikipedia.

John, thank you.
I confess that I have struggled in the past with some of these concepts. Here you lay out the issues with great clarity, so that even a layman like me can grasp the issues. That’s a big help.
LikeLiked by 3 people
I agree, very clear. I have always regarded the use of a model ensemble and the averages of the results as extremely flakey, but never really clearly understood why that should be the case – especially when modelers seem so convinced that their results are so accurate.
Now I know. This should be required reading for all who want to make policy based on models.
Thank you very much.
LikeLiked by 2 people
I’m suspicious of the Gavin Schmidt quote:
This must be for the observations that they already have (and tune the models to). In videos with the late Pat Michaels, he says new data that comes in overwhelmingly falls short of the models and that the latest model to perform best is the Russian model.
LikeLiked by 1 person
Check out 15 minutes into this video. God I miss Pat Michaels!
LikeLike
Thanks, John, a most fascinating and educational romp through uncertainty.
In addition to the issues that you describe, I’d add the following:
1. Common code. A number of the models use common code sections, which may or may not be accurate and valid. This reduces the exploration of the parameter space.
2. Tuning. Models are subjected to three kinds of tuning. The first is the tuning of specific physical parameters. Here’s Gavin Schmidt on the question:
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC6309528/
I love Gavin’s logic. It’s what I call “Climate Hollywood”, the kind of “science” we see in Star Trek and the like—it doesn’t matter if we put in physically impossible parameters, as long as the results look good.
Second, what I call “guardrail tuning”. This is where, when a model goes off the rails, it’s simply nudged back to a physically possible value. For example, the GISS model could not simulate ice melt ponds … so they simply said that the ponds could only form between certain calendar dates. Bad scientists, no cookies. See my post “Meandering Through A Climate Muddle”.
Finally, there is what I call “evolutionary tuning”. Models are constantly being “tested” by seeing if they can hindcast the past, and those that hindcast poorly are either modified or abandoned.
The result of these three kinds of tuning, inter alia, is that climate models with WIDELY differing climate sensitivities are able to successfully hindcast the past. See my post, “Dr. Kiehl’s Paradox”, for a discussion of this.
The result of these abominable practices is to GREATLY limit the exploration of the full parameter space, because they cluster the model results closer to each other in a most unscientific and non-random manner.
My best to you,
w.
LikeLiked by 3 people
If modelling is measurement then it would appear that we have established a method of measuring the future.
LikeLiked by 1 person
“My! What a long tail you have, Climate Model Ensemble.”
“Yes, it’s a tale
with many
twists and
turns of
alea-
tory
and
epi
stem-
ic
un-
cert-
ain-
ty.”
LikeLiked by 1 person
Mark, John,
Thank you for your feedback. I admit that I have already touched on this subject many times before on this website and elsewhere, but I felt it was high time that I took the time to draw the whole thing together and fully explain the issue in as simple a language as I could manage. It was also a response to a request made by a certain Ianalexs, with whom I have had a number of interesting exchanges on this site lately. The result is rather long but I couldn’t see a way of cutting it down without taking liberties with my imagined reader. I am pleased to see that my efforts worked for at least two people. And yes, John, I agree with you that the difficulties in handling mixtures of aleatory and epistemic uncertainty should be better appreciated by a wider audience.
LikeLike
Mike,
I too found that part of Gavin’s quote suspicious, but I didn’t want to dwell on it because it would have complicated further an article that was destined already to be rather long. I thank you for drawing attention to it, however.
LikeLiked by 1 person
There are two further issues I see.
First – I have read that models are parameterised to get an acceptable hindcast, then they remove some or all of the parameters to run the models forward, so they do not even base the projection on the conditions used to train the model.
Second – each model run is based on one of the shared socio-economic pathways, so they do not represent a random spread of results, and give the same weight to a model run that is close to observations as to the most extreme and unlikely case of RCP8.5 model runs.
LikeLike
Willis,
As I have with Mike, I thank you for drawing attention to a number of very important points that I refrained from delving into within my article. The tuning (calibration?) of the models is every bit as problematic as the statistical handling of model ensembles, and the two problems are inextricably linked. An important aspect of epistemic uncertainty is that it isn’t inherent to the system under study but it is inherent to those doing the studying. As such, it can be manipulated, knowingly or otherwise, by the way in which the study is undertaken. I think that is what is behind one of the quotes I gave, i.e. “The distinction between aleatory and epistemic uncertainties is determined by our modeling choices.” This is actually quite a profound and important point. When dealing with a huge state space, a very misleading picture can be painted by concentrating on one area.
LikeLiked by 1 person
Philip,
‘Measuring the future’ is a very good way of putting it. Those who use techniques plucked from the measurement theory toolbox in order to calculate the uncertainty of a projection are attempting to do exactly that. It makes no sense to me. I can just about see why people think it is okay when dealing with a Perturbed Physics Ensemble but I certainly draw the line when they do it with Multi-Model Ensembles.
LikeLike
Beth,
I’ll not attempt a poetic response because I would be out of my depth. However, I will use your reference to fat tails as a pretext for making a further point.
The histogram of ECS values that Tim Palmer included in his book has a fat tail. Palmer explains that this is because of the uncertainty regarding how clouds are likely to affect climate change. Depending upon circumstance, they can be a source of either positive or negative feedback, and there is great deal of uncertainty as to which way this will go. However, most of the climate models presume that the clouds will provide a positive feedback and this is reflected in a skew towards higher ECS predictions. The problem for a lay person such as myself is that I can’t be sure whether this accurately reflects what we already know, or is an epistemic artefact “determined by our modeling choices”. Answers on a postcard please.
LikeLiked by 1 person
Clouds at night ,
Alarmists’ delight?
Clouds in morning,
Sceptics’ warning?
LikeLiked by 2 people
Peter,
>”First – I have read that models are parameterised to get an acceptable hindcast, then they remove some or all of the parameters to run the models forward, so they do not even base the projection on the conditions used to train the model.”
Yes, I have read this also, but I cannot recall where. A citation is needed, if anyone can help us out.
>”Second – each model run is based on one of the shared socio-economic pathways, so they do not represent a random spread of results, and give the same weight to a model run that is close to observations as to the most extreme and unlikely case of RCP8.5 model runs.”
I am not quite sure what your point is here. However, suffice it to say, the uncertainties are compounded when climate models are used as a basis for economic scenario projections.
LikeLike
As an important addendum, I should point out that I had written my article after having read Professor Tim Palmer’s book, but only those chapters dedicated to climate change and weather forecasting. It is true to say that he does not use the terms ‘epistemic’ or ‘aleatory’ within those chapters. However, I have now read his chapter on the modelling of pandemics and, infuriatingly, he arbitrarily returns to the topic of climate change. In doing so, he finally addresses the topic of structural uncertainty (which he terms ‘ontological’ since he deems it to be an unknown unknown). To be precise, he writes the following:
“On a very pragmatic level, the rather difficult issue of the ontological uncertainty of structural model error was addressed by constructing ensembles using multiple models developed in different institutes. In some ways this is no different to the ‘wisdom of the crowd’ concept, where the ‘crowd’ is not the views of members of the public, but the views of differently constructed climate models developed in different institutes.”
Of course, the ‘wisdom of the crowds’ concept holds that a normal distribution will fit the spread of public opinion if enough people are sampled, and that the mean will converge on the truth. It seems that there is no uncertainty, whether epistemic or ontological, that this guy isn’t prepared to think of in aleatoric terms.
LikeLiked by 1 person
“nobody should underestimate the difficulties to be overcome by the climate modellers, since the models concerned will be subject to a number of parametric and structural uncertainties.”
However the models under discussion are intended to produce a simple number – the global average temperature change. The definition of the global temperature change and the data used to arrive at that number have been controversial Nevertheless, the models may well indicate that we will exceed the magic 1.5 degrees centigrade within x number of years. But how do we leap from that relatively minor increase to catastrophic climate breakdown? Is that something that is being modelled or is it just speculation? If climate breakdown is actually being modelled it would be a significantly more complex model than one intended to replicate global average temperature change. The uncertainties would be massive. Likely too many unk unks as Donald Rumsfeld would say.
LikeLiked by 2 people
Potentilla,
Before we could talk about whether a mathematical model can predict climate breakdown, we would need to be sure what we mean by the term ‘breakdown’. Is it something that could have a clear, scientific definition, or is it just more journalistic hyperbole? Are we talking about tipping points here, or perhaps just increased variability with greater extremes or, there again, increased unpredictability? And if unpredictability is the issue, then at what scale are we talking and how is it to be measured? All are legitimate concerns but are the current climate models sufficiently skilful to predict quantitatively at the required scales? As you suggest, it is all well and good to be able to predict a global increase in temperature and quite another to demonstrate how this explains intra-seasonal variability of monsoons resulting from changes in atmospheric teleconnections.
It is strange to think that models can be used to predict breakdown when breakdown can be defined as the point when models fail to predict.
LikeLiked by 1 person
Just to add to my comment above regarding Professor Palmer’s naïve belief that the use of multi-model ensembles can be treated like the ‘wisdom of the crowds’, I offer the following quote from Professor Winsberg:
“Most climate models are highly tunable with respect to some of their variables, and to the extent that no climate lab wants to be the oddball on the block, there is significant pressure to tune one’s model to the crowd…Myles Allen puts the point like this: ‘If modeling groups, either consciously or by “natural selection”, are tuning their flagship models to fit the same observations, spread of predictions becomes meaningless: eventually they will all converge to a delta-function’.”
The more I think about it, the more I become convinced that Palmer’s brilliance as a physicist is actually what is blinding him to the true nature of uncertainty and what it means for the validity of methodology.
Click to access 22.2.winsberg.pdf
LikeLike
I read Eric Winsberg’s book on Philosphy and Climate Science a couple of years ago. I thought it was pretty good. We also wrote a joint post on my blog a few years back.
LikeLike
GIGO principle
LikeLike
ATTP,
Yes, I remember that post. I also remember Professor Eric Winsberg from this:
I recall that you and I had quite an interesting debate regarding Winsberg’s paper: ‘Severe Weather Event Attribution – Why Values Won’t Go Away’. There were some aspects of the paper that I disagreed with but, nevertheless, I had this to say:
“Anyone who publishes on the uncertainties associate with climate modelling before turning his attention to the philosophical implications of Hawking Radiation is someone I would gladly share a pint with.”
The more I read of Professor Winsberg’s position on climate modelling, the more I find myself agreeing with him. Perhaps I should save up some more pennies to buy his book. Unfortunately, I blew them all on Professor Tim Palmer’s. It provided a fascinating insight, but I can’t say that I came away convinced that he was as fully up to speed as Winsberg is on the relevant philosophy.
LikeLiked by 2 people
Stew,
>”GIGO principle”
Indeed. There seems to be a view held by some that having a fancy statistical technique to do lots of number crunching, producing very scientific-looking probability distributions, can somehow compensate for poor quality input. In the one end goes sparse data that oozes epistemic uncertainty, and out the other comes a nice graph that oozes scientific objectivity. An excellent example of this is provided in Palmer’s book when he discusses how ensemble statistics elevated Covid guesswork into an uncertainty analysis you could trust your lockdown policy on. Palmer explains it thus when he talks about dealing with parametric uncertainty in the COVIDSim model:
“In 2021, a study was published of ensemble projections with COVIDSim in which these uncertain parameters were varied according to plausible estimates of their uncertainty. These estimates were obtained by what is called ‘expert solicitation’, which means asking the experts how much they felt a parameter value could be in error: 10 percent, 20 percent, 50 percent? Ensembles were then run in which the parameters were randomly perturbed by the experts’ estimates of parameter uncertainty.”
In other words, pure epistemic uncertainty was analysed using a technique designed solely for aleatory uncertainty. As a consequence, the ensemble analysis would be pure pants. But at least it would be scientific smarty pants, and so everyone, including Palmer, would be suitably impressed.
LikeLiked by 2 people
Having now read all of Tim Palmer’s book (not just the chapters on weather forecasting and climate change) it is abundantly obvious that he is fully committed to the ensemble techniques he developed for weather forecasting and he sees nothing wrong with using the same approach for all circumstances. Consequently, all fields of predictive modelling, such as for epidemiological, virus transmutation, economic, stock market, and even world politics and conflict risk, are seen as perfect candidates for the ensemble approach. He seems to believe that all you need is a big enough ensemble of sufficiently complex models, and a big enough computer to number crunch the stochasticity!
I have to admit that the warning signs were in the book’s subtitle when it referred to the ‘science of uncertainty’. This turned out to be an allusion to the manner in which inherent variability can be objectively predicted. That’s fine, but it isn’t okay to then transfer that idea into areas of uncertainty that are truly both subjective and deterministic. Palmer doesn’t seem able to see the problem and even resorts to using the language of physical perturbation ensembles when using ensemble techniques to measure purely epistemic uncertainty. When he talks of parameters being “randomly perturbed by the experts’ estimates”, one has to wonder in exactly what way an individual’s opinion can perturb a parameter, randomly or otherwise.
Come back Peter Gleick, all is forgiven!
LikeLiked by 2 people
A particular problem that I had with the Tim Palmer book was the author’s annoying habit of returning to climate change issues long after he had supposedly moved on to entirely unrelated subjects. Consequently, there are quite a few choice quotes that I didn’t use in my article simply because I wrote it before reading his thoughts on non-climate related stuff (i.e., pandemics, stock market crashes, risk analysis, war, creativity, free will, consciousness, religion, etc.). For example, there is the following quote that is buried in a chapter that is supposed to be about how the brain works and how noise in axon signals explains certain aspects of decision-making:
“Indeed, it makes sense to try to construct an ensemble of worlds where these different pros and cons are realised. One doesn’t need to actually derive probabilities from such an ensemble. Merely constructing ‘storylines’ portrayed in individual ensemble members is itself an important step. In fact, the idea of ensemble members as plausible ‘storylines’ is becoming important in climate science, in situations where probabilities are difficult to compute.”
But in climate science it isn’t a matter of probabilities being difficult to compute for ensemble members; it is a matter of them being meaningless to compute. It’s almost as though he is unaware that the ‘storyline’ approach he speaks of was developed by those who completely reject the idea that the range of climate model ensemble projections can be treated probabilistically.
I know it’s a bit late to be mentioning it now, but I thought I should because it confirms what I had suspected about Professor Palmer’s thinking on probability and climate model ensembles.
P.S. Palmer believes that axon noise can explain intuitive thinking. However, in coming to this conclusion he totally ignores the role played by the emotional centres of the brain. Hint: if you want a thesis on how the brain works you should go to a neurologist rather than consult a physicist.
LikeLiked by 2 people
John
I’m reading a S/F book at the moment called “the doors of Eden” by Adrian Tchaikovsky.
seems like fiction & climate fact are merging when ‘storyline’ is used.
ps – maybe o/t
LikeLike
Hi John, thank you for this post, which I read soon after it was published, before there were any addenda about Tim Palmer in comments. This is what I thought of saying in response:
Before the addenda. But they have strengthened my conviction in 2.
LikeLike
Richard,
“Tim Palmer is a charlatan.”
I’d say it is a little more complicated than that. He has written a far-reaching book that takes his very authentic expertise in one particular area (the physics and mathematics of chaos) and uses it to address a number of questions of general interest. When he is talking about physical perturbation ensembles and the construction of weather forecasts, he is on his own turf and speaks with great authority. When he ventures further and seeks to apply his expertise in other areas, he starts to come across as being too confident in his position. After a while, the reader begins to discover that having more complex models, in bigger ensembles, using more Monte Carlo simulation, is his answer to everything. The problem here, I feel, is that he thinks that ‘the science of uncertainty’ (the title of part 1 of his book) is all you need to know in order to investigate the uncertainty of science.
I am an avid reader of this sort of book, and I will not say I didn’t enjoy it. The chapter on his invariant set hypothesis, as a theory in foundational physics, was particularly interesting. But there again, he was back on his own turf. The problem is that the book also included chapters on subjects such as decision theory, for which he is obviously a layman inclined to make basic errors. The difficulty is in separating the wheat from the chaff, because, like all experts, his self-confidence never falters.
LikeLiked by 1 person
John: I have limited time and for that reason, and others, I don’t resile from my concise summary of Palmer’s contribution in the climate area. I’m no doubt influenced by what Jerome Booth said, with Peter Lilley in strong support, at the House of Commons on Thursday night. Again, my interpretation: Lawson has convinced Booth that there is a need for respected people to go public about the climate madness. Booth has taken the plunge. At the event Michael Kelly made a profound point about computer models, illustrating his point from pandemics in the recent past (when models were trusted far too much) and the more distant past (when they didn’t exist and the outcome was much better). Toby Young also made a profound contribution ‘from the floor’ – the first time I’ve seen Young at a GWPF-related event. Brave guy. Courage applied to climate. Relevant.
I’ve also been thinking more about Enrico Fermi and his response to Freeman Dyson before quarks had been ‘invented’ as Dyson puts it. The ultimate epistemoloogical uncertainty where a real expert could nonetheless be right, well ahead of time, that Dyson’s model was wrong. Dyson wasn’t a charlatan, just mistaken, and proved this by shutting down his multi-person team. Because of the expert’s ‘amazing intuition’. See https://www.youtube.com/watch?v=hV41QEKiMlM and the transcript provided.
That story drives a truck through a lot of stuff, including some cherished beliefs of some climate sceptics about the role of experts. But another time.
LikeLiked by 1 person
Richard,
Dyson’s anecdote is always worth recalling on these occasions. One wonders what advice he might have received had he gone to Palmer instead of Fermi. I’m guessing that Palmer would have suggested a bit of Monte Carlo simulation to pin down the uncertainty resulting from Dyson’s four free parameters. This is exactly what I meant by the science of uncertainty not necessarily being the best way of addressing the uncertainty of science.
Speaking of Youtube interviews, you will note that there is no shortage of online interviews of Professor Palmer plugging his book. The one below is particularly germane because there is a point (about 13 minutes in) where he responds to the Feynman quote about science being the belief in the ignorance of experts:
You will note that Palmer disagrees with Feynman, preferring instead to refer to the fallibility of experts. However, he completely ignores the real importance of the question, which is the gap between the existence of fallibility and the self-awareness of fallibility. I use the word ‘ignores’ here deliberately since it illustrates why Feynman was right to refer to ‘ignorance’.
LikeLiked by 1 person
If anyone is still interested, I have written an Amazon review of the Tim Palmer book. As the review’s title I have used the point that the uncertainty in science cannot be fully addressed by the so-called ‘science of uncertainty’. You can check it out here:
https://www.amazon.co.uk/gp/customer-reviews/R3UWA5A3696G52/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=0192843591
LikeLiked by 2 people
That sounds fascinating on the Feynman quote John. Haven’t looked at the video or your review as yet but write briefly here in general support 😉
LikeLiked by 1 person
Richard,
Thank you for your support.
To elucidate further, I offer the Feynman quote in its context:
“Science is the belief in the ignorance of experts. When someone says, ‘Science teaches such and such,’ he is using the word incorrectly. Science doesn’t teach anything; experience teaches it. If they say to you, ‘Science has shown such and such,’ you might ask, ‘How does science show it? How did the scientists find out? How? What? Where?’ It should not be ‘science has shown’ but ‘this experiment, this effect, has shown.’ And you have as much right as anyone else, upon hearing about the experiments–but be patient and listen to all the evidence–to judge whether a sensible conclusion has been arrived at. (…) The experts who are leading you may be wrong. (…) I think we live in an unscientific age in which almost all the buffeting of communications and television — words, books, and so on – are unscientific. As a result, there is a considerable amount of intellectual tyranny in the name of science.” (The Pleasure of Finding Things Out, p.187).
As you can see, the problem is not an absence of understanding, but a misplaced confidence that we do understand just because the experts say so. The last part of the quote is worth repeating:
“As a result, there is a considerable amount of intellectual tyranny in the name of science.”
Amen to that!
LikeLiked by 2 people
If the only thing that interests you about Tim Palmer’s book is the science behind his use of Monte Carlo simulation for weather forecasts, then you don’t have to fork out to buy it; you can just read the following paper:
https://www.researchgate.net/publication/316322885_The_primacy_of_doubt_Evolution_of_numerical_weather_prediction_from_determinism_to_probability_EVOLUTION_OF_WEATHER_PREDICTION
You will note from the above paper that the stochastic physics referred to in my article goes by the rather grand term ‘Stochastically Perturbed Parametrization Tendency scheme (SPPT)’, and if you are really interested to know more about it you can read this:
Click to access 16923-stochastic-representations-model-uncertainties-ecmwf-state-art-and-future-vision.pdf
I think the important point to understand is that the model uncertainties that are being modelled here stochastically (using SPPT, which is itself an application of Monte Carlo simulation) reflect inherent variability, even though they are parametric. It’s not like a die with an unknown number of sides so much as a collection of dice that are not quite perfect cubes, and for which the level of imperfection can be treated as a random factor having a physical basis. I take Palmer at face value when he says that the success rate of predictions improved with SPPT and so I assume that there is no deterministic incertitude being mishandled here. However, remember that this is just weather forecasting with physical perturbation ensembles, which is a far cry from climate projections based upon ensembles of differently structured models that have been tuned to taste.
LikeLiked by 4 people
You don’t have to search very far to find that Professor Palmer has a long history of pushing his notion of uncertainty (the one beloved of many scientists when they talk of the science of uncertainty). Here, for example, is an advert for such a talk given by Palmer at Oxford University back in 2015:
https://www.oxfordmartin.ox.ac.uk/events/climate-change-dealing-with-uncertainty-by-prof-tim-palmer-cbe/
Apparently the talk gave the answer to three important questions, the first two of which were posed thus:
“Firstly, what are the physical reasons why predictions of climate change are necessarily uncertain? Secondly, how can we communicate this uncertainty in a simple but rigorous way to those policy makers for whom uncertainty quantification may seem an unnecessary complication.”
The third question, unfortunately, wasn’t as follows: To what extent is the simplicity and rigour misleading because, when all is said and done, modelling isn’t measurement?
This is the main reason why the spread of climate projections is treated by climate scientists as a probability density function — because it’s simple and rigorous! But simplicity is no good to the policy maker when it is simplistic, and rigour is worse than useless when it is rigorously wrong.
There is a scientist’s hubris to all of this. The policy makers do not look upon uncertainty quantification as an unnecessary complication, but when they do look to its quantification they trust at least that it is being quantified by someone who has fully grasped the concept. This has been a misplaced trust, I fear.
LikeLiked by 2 people
This is an excellent article. Well done John. I’ve never got on with statistics; in fact I hated it at school. This article makes me think that (grudgingly), me and statistics might become, if not exactly friends, then at least acquaintances.
I fear it is worse than we thought though.
You say:
“The problems only emerge when epistemic uncertainty features in the system’s mathematical model and this is not properly isolated, and allowed for, when assessing the extent to which the probability distributions produced by the simulation fully capture the uncertainty.”
Not only have they failed to isolate the epistemic uncertainty (cloud/aerosol forcings, solar forcings, internal variability etc.) from the aleatory uncertainty (basically by ignoring it), they have also assigned aleatory status to uncertainty which should really be epistemic. The alleged aleatory component of the climate models I presume to be ‘known greenhouse gas radiative forcing’. But that in itself is not ‘known’ because the ‘enhanced greenhouse effect’ – where radiative forcing from anthropogenic GHGs is amplified by positive water vapour feedbacks – gives a climate sensitivity in the models anywhere between 1C to 6C, with the ‘best guess range being 1.5C to 4.5C.
Professor Jeroen Pieter van der Sluijs makes this clear:
“Being the product of deterministic models, the 1.5°C to 4.5°C range is not a probability distribution. There have, nevertheless, been attempts to provide a ’best guess’ from the range. This has been regarded as a further useful simplification for policy-makers. However, non-specialists – such as policy-makers, journalists and other scientists – may have interpreted the range of climate sensitivity values as a virtual simulacrum of a probability distribution, the ’best guess’ becoming the ’most likely’ value.”
So if climate scientists were to ‘isolate’ the epistemic uncertainty from the aleatory then what they would be left with is just 100% epistemic uncertainty, which would not lend itself to being modelled as a probability density function at all!
LikeLiked by 1 person
>”So if climate scientists were to ‘isolate’ the epistemic uncertainty from the aleatory then what they would be left with is just 100% epistemic uncertainty, which would not lend itself to being modelled as a probability density function at all!”
Well, I guess you’re right Jaime. The point is that you can have a mathematical model that includes parametric uncertainties that are essentially aleatoric, i.e. where the variability is inherent and measurement theory applies. You can also run such models repeatedly to see how varying the values of those parameters changes the projections. And this is all very well — Professor Palmer has made a good living doing that. But when you start looking at variables for which the possible range of values has more to do with expert disagreement rather than the vagaries of measurement, something different is happening. And once you start dealing with collections of models that are structurally different but have similarities that have more to do with the focus of research rather than anything else, then that’s something again. There has to come a point when one stops pretending that the uncertainty is inherent to the system rather than within those looking at it.
And thanks for the feedback. It is always appreciated. That’s why I cracked open the champagne when Fenton gave it the thumbs up 🙂
LikeLiked by 2 people
John,
“The point is that you can have a mathematical model that includes parametric uncertainties that are essentially aleatoric, i.e. where the variability is inherent and measurement theory applies.”
Hmm. Whereas I was hoping my uncertainty about statistical uncertainty might be essentially aleatory, I still find that it has significant epistemic elements!
LikeLike